本文,我会从『缓存』、『CPU 高速缓存』说起,然后结合 JMM 来帮助大家逐步学习和理解 volatile 的用法和原理。
缓存
做过后端开发的同学都一定听说过 Redis 、Memcache 这些缓存,也经常使用,那么为什么需要缓存呢?
因为数据库读写都要操作磁盘,而磁盘的读写速度和内存的读写速度差别太大了,在高并发情况下,数据库很可能会首先成为性能瓶颈(虽然很多公司的业务并没有什么并发量)。所以 Redis 、Memcache 这些缓存都是为了提高数据的读写速度,进而提高网站响应速度的,但必然要面临的一个问题是『缓存一致性』,即缓存中数据和数据库中数据的一致性问题。本文不再赘述,见我的另一篇博客。
CPU 高速缓存
CPU 也有缓存,前面说了『磁盘的读写速度和内存的读写速度差别巨大』,而内存的读写速度和 CPU 比起来的也是差别巨大,所以 CPU 也有它自己的缓存,具体来说有一级缓存,二级缓存,三级缓存,有的缓存在 CPU 内部,有的在 CPU 外部,不过对于本文我想讲述的问题来说这不重要,只用知道,CPU 读写数据时会先检查数据是否在 CPU 高速缓存中,如果在就对其进行读写,再在合适的时机将数据刷新回主存;如果不在则 CPU 就会访问主存然后再将数据放进 CPU 高速缓存中。所以对于 CPU 缓存中的同一个数据,多个线程同时读取并计算的时候,就可能会出现数据准确性的问题。(比如 CPU 缓存中的数据 i=0,两个线程同时读取到 i=0并进行自增,最后结果 i=1,这显示是错误的;又比如对于同一个数据,多个线程都对其进行了更新并将更新后的数据放进了不同的 CPU 高速缓存中,则该数据在从 CPU 高速缓存刷新回主存时就有可能不准确)。
为了解决 CPU 缓存导致的缓存一致性问题,有关部门制定了『缓存一致性协议』,主要是制定 CPU 缓存与主存交互时的规范。不同的 CPU 其缓存一致性协议也不同。而操作系统我们知道,它屏蔽了底层硬件的操作细节,它需要提供接口给外部程序调用,所以操作系统也要定义一套规范,来解决 CPU 缓存数据一致性的问题,而『内存模型』就是这样一套规范,而不同操作系统如 Linux 和 Windows 的『内存模型』肯定是不一样的。
JVM 内存模型(JMM)
JVM 是跨平台的虚拟机,而虚拟机我们知道,是通过软件模拟的具有完整硬件系统功能的计算机系统,所以 JVM 有它自己的『内存模型』即 JMM ,JMM 规定了线程之间的共享变量要保存在『主存』当中,每个线程有自己的『工作内存』(抽象概念),每个线程更新共享变量时需要先将共享变量从 『主存』 中读进线程自己的『工作内存』,在『工作内存』中更新完之后再写回『主存』中。于是乎,这也产生了线程安全的问题。
|
1 2 3 4 5 6 7 8 9 |
class MyThread extends Thread { public static int num = 0; @Override public void run() { for (int i = 0; i < 10000; i++) { num++; } } } |
上面的线程类,不用创建很多个对象,只用创建两个 MyThread 对象并运行,就能看到线程安全的问题,num 最终的值并不是期望的 20000 。原因就是因为共享变量 num 是保存在『主存』中的,每个线程都会从『主存』中读取 num 的值到自己的『工作内存』当中进行自增,然后将值再写回『主存』之中,这就必然会导致线程安全的问题。
volatile 的含义
上面的程序中,如果用 volatile 修饰变量 num 是否能解决线程安全的问题呢,你可以试一下,会发现用 volatile 修饰 num 依然存在线程安全的问题。
那么 volatile 到底是什么作用呢?
简而言之,用 volatile 修饰了 num ,则该 num 变量会被标记为存储在『主存』中,每个线程都会直接读取并修改『主存』中的 num 的值,保证了不同线程中该变量的可见性。(但这并不能保证线程安全,如上面例子所示仍然会存在线程安全的问题)
那么 volatile 适用于什么场景呢?一般符合下面两种场景,就可以使用 volatile :
- 变量的运算结果并不依赖于变量的当前值,或能够保证只有单一的线程修改变量的值。
- 变量不需要与其他的状态变量共同参与不变约束。
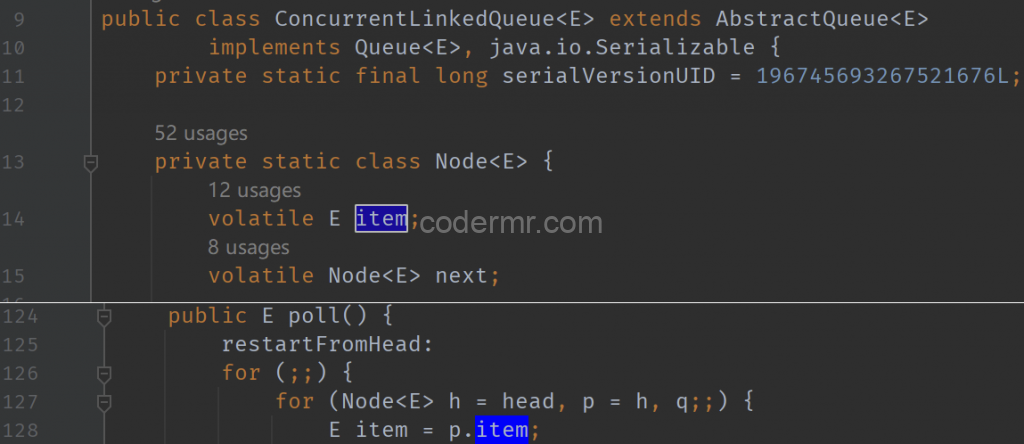
再具体一点来说,就是 volatile 修饰的变量,不能在该变量的基础上对该变量进行修改(比如 i++ 就是在 i 值的基础上进行修改)。volatile 通常的用法是,直接在方法内部给 volatile 变量赋值,比如 JDK 源码中 ConcurrentLinkedQueue 的源码里面:
再说 volatile 的可见性
上面说了,被 volatile 修饰的变量,能够在不同线程之间保持可见性。但是,仅仅是被 volatile 修饰的这个变量才能在不同线程之间保持可见性吗?
并不是。
volatile 的可见性保证如下:
- 【可见性定理一】如果线程 A 写入一个 volatile 变量,而线程 B 随后读取了同一个 volatile 变量,那么线程 A 在写入 volatile 变量之前对线程 A 可见的所有变量,在线程 B 读取 volatile 变量之后也对线程 B 可见。
- 【可见性定理二】如果线程 A 读取一个 volatile 变量,那么在读取该 volatile 变量时线程 A 可见的所有变量,也将从主存储器中重新读取。
下面举两个例子来理解上面两点。
|
1 2 3 4 5 6 7 8 9 10 |
public class TestObj { private int num1; private int num2; private volatile int num3; // 只有 num3 这个变量被 volatile 修饰了 public void update(int num1, int num2, int num3){ this.num1 = num1; this.num2 = num2; this.num3 = num3; } } |
如上,只有 num3 这个变量被 volatile 修饰了(num3 这个变量会被标记为存储在主存中),然后在 update() 方法中对 num3 进行了写入操作,根据【可见性定理一】对于线程可见的变量 num1 和 num2 也同样会被标记为存储在主存中,所以对变量 num1、num2、num3 的读写都是基于主存进行的。
指令重排序
volatile 还可以禁止对其修饰的变量进行指令重排序,关于指令重排序见文章:关于指令重排序。
关于 i++
i++ 并不是一个原子操作,它的执行过程如下:
- 从主存中读取变量 i 副本到线程的工作内存
- 给 i 加 1
- 将 i 加 1 后的值写回主存